
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- batchInsert
- JSON 분리
- multi update
- spring webflux
- 폐기하기
- 스프링 배치 공식문서
- JSONObject 분할
- JSONArray 분할
- org.json
- git stage
- 마이바티스 트랜잭션
- 성능개선
- Meta Table
- 문자형을 날짜형으로
- ChainedTransactionManager #분산데이터베이스 #Spring Boot #MyBatis
- 날짜형을 문자형으로
- 스프링 웹플럭스
- str_to_date
- 스테이지에 올리기
- spring reactive programming
- 스프링 배치 메타 테이블
- date_format
- JobExecutionAlreadyRunningException
- JSON 분해
- JSON 분할
- 마리아디비
- jar 소스보기
- 무시하기
- nonblocking
- 스프링 리액티브 프로그래밍
- Today
- Total
ebson
[신입 SQL 교육 자료] JOIN, SUBQUERY, 계층형쿼리 본문
4. JOIN
4.1. 개념
- 두 개 이상의 테이블들을 연결 또는 결합하여 데이터를 출력하는 것
- 관계형 데이터베이스의 핵심 기능
- 일반적으로 PK, FK에 의해 JOIN이 성립됨
- JOIN은 항상 두개의 집합 간에만 이루어짐
=> 즉, A, B, C 테이블을 JOIN하면 A, B 테이블을 먼저 JOIN하고 이 JOIN으로 생성된 새로운 테이블과 C 테이블을 JOIN함
- 테이블의 JOIN 순서를 옵티마이저가 결정함
- 분할된 여러 개의 테이블들로부터 데이터를 조회하기 위해 테이블들 간의 논리적인 연관관계가 필요하고 이것을 표현하는 것이 JOIN임
4.2. 종류
4.2.1. EQUAL JOIN
- 두 개의 테이블 간에 컬럼 값들이 정확히 일치하는 경우 사용함
4.2.1.1. ORACLE JOIN
SELECT T1.C1, T2.C1
FROM T1, T2
WHERE T1.C1 = T2.C1;
4.2.1.2. ANSI JOIN
SELECT T1.C1, T2.C1
FROM T1
INNER JOIN T2
ON T1.C1 = T2.C1;
- 테이블명에 ALIAS를 주고 JOIN 조건절에 사용할 수 있음
- N 개의 테이블을 JOIN 할 때 JOIN 조건은 N-1개가 필요함
4.2.2. NOT EQUAL JOIN
- BETWEEN, >=, <=, >, < 연산자를 사용해 JOIN을 수행함
- 두 개의 테이블 간에 컬럼 값들이 정확히 일치하지 않는 경우에 사용함
Ex)
SELECT E.ENAME, E.SALARY, S.GRADE
FROM EMPLOYEE E, SALARY_GRADE S
WHERE E.SALARY BETWEEN S.MIN_SAL AND S.MAX_SAL;
4.3. 원리
- JOIN이란 두개 이상의 테이블을 하나의 집합으로 만드는 연산임
- JOIN 기법으로는 NESTED LOOP JOIN, HASH JOIN, SORT MERGE JOIN 등이 주로 사용됨
4.3.1. NESTED LOOP JOIN
- 중첩된 반복문과 유사한 방식으로 JOIN을 수행함
- 반복문 외부의 테이블을 선행 테이블, 내부의 테이블을 후행 테이블 이라고 함
- 선행 테이블의 조건을 만족하는 행들을 추출하고 후행 테이블을 읽으면서 JOIN을 수행함
- 선행 테이블의 조건을 만족하는 행들의 수만큼 반복 수행함
*사용시 참고사항
결과 행의 수가 적은 테이블을 JOIN 순서상 선행 테이블로 선택하는 것이 성능상 유리함
랜덤 방식으로 액세스 하므로 처리 범위가 좁은 것을 조건으로 선택하는 것이 유리함
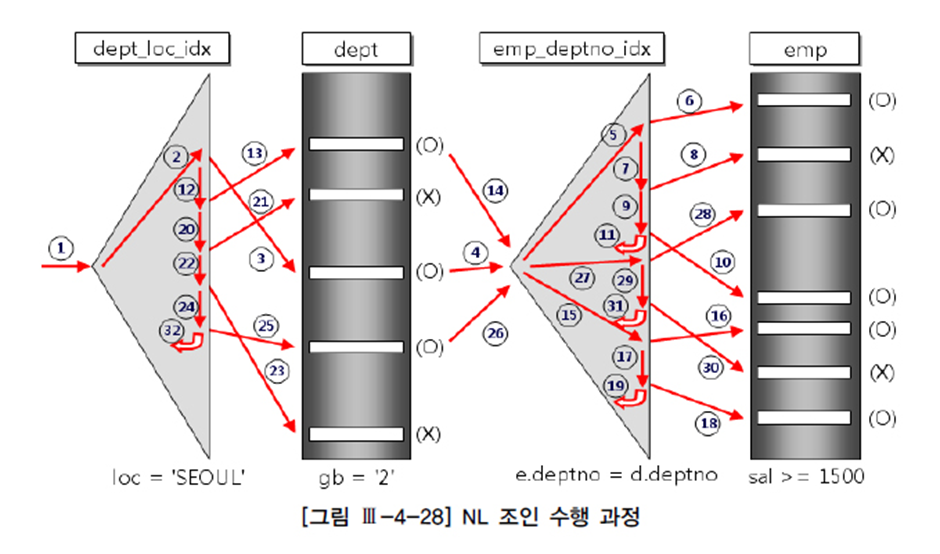
*예제 SQL
SELECT /*+ ordered use_nl(e) */
E.EMPNO, E.ENAME, D.DNAME, E.JOB, E.SAL
FROM DEPT D, EMP E
WHERE D.DEPTNO = E.DEPTNO ............①
AND D.LOC = 'SEOUL'.................②
AND D.GB = '2'......................③
AND E.SAL >= 1500...................④
ORDER BY SAL DESC
- 1) 사용되는 인덱스 : DEPT_LOC_IDX, EMP_DEPTNO_IDX
- 2) 조건비교 순서 : ② → ③ → ① → ④

4.3.2. SORT MERGE JOIN
- JOIN 컬럼을 기준으로 데이터를 정렬해 JOIN을 수행함
- JOIN 컬럼에 인덱스가 있으면 SORT 과정을 생략하고 바로 JOIN할 수도 있음
- 램덤 액세스 하기에는 부담이 되는 넓은 범위의 데이터를 처리할 때 사용함
- 정렬할 데이터가 많아 모든 정렬작업을 수행하기가 어려운 경우 임시영역을 사용하므로 성능 저하를 유발할 수 있음
- HASH JOIN과 달리 동등 조건 뿐만 아니라 비 동등 조건에 대해서 JOIN 작업이 가능함
*예제 SQL
SELECT /*+ ordered use_merge(e) */ D.DEPTNO, D.DNAME, E.EMPNO, E.ENAME
FROM DEPT D, EMP E
WHERE D.DEPTNO = E.DEPTNO
*사용시 참고사항
- 컬럼의 인덱스가 없을 경우에도 사용 가능함
- JOIN 작업을 위해 항상 정렬 작업이 발생하는 것은 아님
- 실제 JOIN 수행 과정이 NESTED LOOP JOIN 과 크게 다르지 않고 OUTER 집합과 INNER 집합을 미리 정렬해 둔다는 점만 다름
- OUTER 집합의 N번 ROW에 대해 INNER 집합의 로우들을 순서대로 SCAN해 JOIN을 시도하고 실패한 순서부터 N+1번 ROW가 스캔을 이어감
- 스캔위주의 JOIN 방식임. INNER 테이블을 반복 액세스 하지 않기 때문에 MERGE 과정에서 RANDOM 액세스가 발생하지 않음
- 일반 인덱스나 클러스터형 인덱스 등의 미리 정렬된 오브젝트를 사용하면 정렬작업 없이 JOIN을 수행하므로 더욱 효율적임
4.3.3. HASH JOIN
- HASH JOIN 은 해쉬 기법을 사용해 JOIN을 수행함
- JOIN 컬럼을 기준으로 해쉬 함수를 수행해 동일한 해쉬 값을 갖는 것들 사이에서 실제 값이 같은지를 비교하면서 JOIN을 수행
- NESTED LOOP JOIN의 랜덤 액세스 방식의 단점과 SORT MERT JOIN의 정렬 작업 방식의 단점을 보완함

*사용시 참고사항
- JOIN 컬럼의 인덱스가 존재하지 않아도 사용가능
- 해쉬 함수를 이용하므로 동등조건에서만 사용할 수 있음
- 해쉬 테이블을 생성하기 위한 메모리가 필요함
- 메모리에 적재할 수 있는 영역을 초과하면 임시 디스크 영역에 해쉬 테이블을 저장함
- 결과 행의 수가 적은 테이블을 선행 테이블로 사용하는 것이 좋음
- 선행 테이블을 BUILD INPUT이라고 하고 후행 테이블을 PROBE INPUT이라고 함
- 한쪽 테이블이 가용 메모리에 담길 정도로 작아야 함
4.4. OUTER JOIN
4.4.1. 개념
- EQUAL JOIN을 생성하려는 두 개의 테이블의 한쪽 컬럼에서 값이 없다면 데이터를 반환하지 못함
- 동일 조건에서 JOIN 조건을 만족하는 값이 없는 행들을 조회하기 위해 사용함
- 연산자는 (+) 임
- JOIN 시 값이 없는 테이블 우측에 (+) 연산자를 표시함
- 연산자는 표현식의 한 측 테이블에만 쓸 수 있음
- 연산자를 표시한 테이블에 대해 추가로 조건절이 있으면 연산자를 모두 표시해야 함.
4.4.2. 예문
4.4.2.1. 연산자를 사용, ORACLE JOIN
SELECT DISTINCT(a.deptno), b.deptno
FROM emp a, dept b
WHERE a.deptno(+) = b.deptno
AND a.ename(+) LIKE '%';
4.4.2.2. LEFT OUTER JOIN
오른쪽 테이블에 JOIN시킬 컬럼이 없는 경우 사용함
SELECT DISTINCT(e.deptno), d.deptno
FROM dept d
LEFT OUTER JOIN emp e
ON d.deptno = e.deptno;
4.4.2.3. RIGHT OUTER JOIN
왼쪽 테이블에 JOIN시킬 컬럼의 값이 없는 경우 사용함
SELECT DISTINCT(e.deptno), d.deptno
FROM emp e
RIGHT OUTER JOIN dept d
ON e.deptno = d.deptno;
4.4.2.4. FULL OUTER JOIN
양쪽 테이블 모두 OUTER JOIN을 걸어야 하는 경우 사용함
SELECT DISTINCT(e.deptno), d.deptno
FROM emp e
FULL OUTER JOIN dept d
ON e.deptno = d.deptno;
5. SUBQUERY
5.1. 개념
- 하나의 SQL 문 안에 포함된 또다른 SQL문임
- 서브쿼리는 알려지지 않은 기준을 이용한 검색을 위해 사용함
- 메인쿼리가 서브쿼리를 포함하는 종속적인 관계임
- 단일행 또는 복수행 비교 연산자와 함께 사용 가능함
- MySQL, MariaDB에서는 ORDER BY를 사용하지 못함. ORDER BY는 메인쿼리의 마지막 문장에 위치함
- SELECT절, FROM절, WHERE절, HAVING절, ORDER BY절, INSERT VALUES 절, UPDATE SET 절에 올 수 있음
5.2. 종류
5.2.1. 비연관 서브쿼리
- 서브쿼리가 메인쿼리 컬럼을 가지고 있지 않음. 메인쿼리에 서브쿼리가 실행한 값을 제공하는 목적이 주임
SELECT (SELECT NAME1
FROM COMMON_CODE
WHERE MAJOR_CODE = 'C01'
AND MINOR_CODE = 'AE')
, T.C1
, T. C2 ...
FROM TB1 T
5.2.2. 연관 서브쿼리
- 서브쿼리가 메인쿼리 컬럼을 가지고 있음. 일반적으로 메인쿼리가 먼저 수행되어 읽혀진 데이터로 서브쿼리에서 조건이 맞는지 확인함
SELECT T.TEAM_NAME, M.PLAYER_NAME, M.POSITION, M.BACK_NO, M.HEIGHT
FROM PLAYER M, TEAM T
WHERE M.TEAM_ID = T.TEAM_ID
AND M.HEIGHT < ( SELECT AVG(S.HEIGHT)
FROM PLAYER S
WHERE S.TEAM_ID = M.TEAM_ID
AND S.HEIGHT IS NOT NULL
GROUP BY S.TEAM_ID )
ORDER BY M.PLAYER_NAME;
5.2.3. 단일 행 서브쿼리
- 서브쿼리의 실행 결과가 항상 1건 이하임. 단일 행 비교 연산자(=, <, <=, >, >=, <>)와 함께 사용함
SELECT PLAYER_NAME, POSITION, BACK_NO
FROM PLAYER
WHERE TEAM_ID =
( SELECT TEAM_ID
FROM PLAYER
WHERE PLAYER_NAME = '정남일'
)
ORDER BY PLAYER_NAME;
5.2.4. 다중 행 서브쿼리
- 서브쿼리의 실행결과가 여러 건인 서브쿼리임. 다중 행 비교 연산자(IN, ALL, ANY, SOME, EXISTS)와 함께 사용함
* IN vs EXSITS
IN - ROW의 해당 컬럼 값을 직접 비교
EXISTS - 조건에 맞는 ROW의 존재 유무만을 확인
=> 일반적으로 IN 보다 EXISTS를 사용하는 경우가 성능상 유리함
NULL 에 대해 NOT EXISTS 는 TRUE를, NOT IN 은 FALSE를 반환
SELECT REGION_NAME, TEAM_NAME, E_TEAM_NAME
FROM TEAM
WHERE TEAM_ID IN
( SELECT TEAM_ID
FROM PLAYER
WHERE PLAYER_NAME = '정현수')
ORDER BY TEAM_NAME;
5.2.5. 다중 컬럼 서브쿼리
- 서브쿼리의 실행 결과로 여러 컬럼을 반환함. 메인쿼리의 조건절에 여러 컬럼을 동시에 비교함. 서브쿼리와 메인쿼리에서 비교하는 컬럼 개수와 위치가 동일해야 함
SELECT TEAM_ID, PLAYER_NAME, POSITION, BACK_NO, HEIGHT
FROM PLAYER
WHERE (TEAM_ID, HEIGHT) IN
( SELECT TEAM_ID, MIN(HEIGHT)
FROM PLAYER
GROUP BY TEAM_ID)
ORDER BY TEAM_ID, PLAYER_NAME;
5.3. 그 밖의 서브쿼리 종류
5.3.1. 스칼라 서브쿼리
한행, 한컬럼만을 반환함
컬럼을 쓰는 대부분의 곳에서 사용함
SELECT PLAYER_NAME, HEIGHT
, ( SELECT AVG(HEIGHT)
FROM PLAYER X
WHERE X.TEAM_ID = P.TEAM_ID) 팀평균키
FROM PLAYER P;
5.3.2. FROM절의 서브쿼리
인라인 뷰라고 함. 테이블이 올 수 있는 곳에서 사용함
SELECT T.TEAM_NAME, P.PLAYER_NAME, P.BACK_NO
FROM
( SELECT TEAM_ID, PLAYER_NAME, BACK_NO
FROM PLAYER
WHERE POSITION = 'MF'
) P
, TEAM T
WHERE P.TEAM_ID = T.TEAM_ID
ORDER BY P.PLAYER_NAME;
5.3.3. HAVING 절의 서브쿼리
그룹함수와 함께 사용할 때 그룹핑된 결과에 대해 부가적인 조건을 주기 위해 사용함
SELECT P.TEAM_ID, T.TEAM_NAME, AVG(P.HEIGHT)
FROM PLAYER P, TEAM T
WHERE P.TEAM_ID = T.TEAM_ID
GROUP BY P.TEAM_ID, T.TEAM_NAME
HAVING AVG(P.HEIGHT) < (SELECT AVG(HEIGHT)
FROM PLAYER
WHERE TEAM_ID ='K02');
5.3.4. UPDATE SET 절의 서브쿼리
UPDATE TEAM A
SET A.STADIUM_NAME = (SELECT X.STADIUM_NAME
FROM STADIUM X
WHERE X.STADIUM_ID = A.STADIUM_ID);
5.3.5. INSERT VALUES 절의 서브쿼리
INSERT
INTO PLAYER
( PLAYER_ID, PLAYER_NAME, TEAM_ID )
VALUES(
(SELECT TO_CHAR(MAX(TO_NUMBER(PLAYER_ID))+1) FROM PLAYER)
, '홍길동', 'K06');
5.5. 뷰(VIEW)
5.5.1. 개념
테이블이 실제로 데이터를 가지는 반면 뷰(VIEW)는 데이터를 가지고 있지 않음. 뷰는 뷰 정의만을 가지고 있음.
뷰는 실제 데이터를 가지고 있지 않지만 테이블이 수행하는 역할을 수행하기 때문에 가상 테이블이라고도 함
5.5.2. 특징
독립성 – 원본 테이블 구조가 변경되어도 뷰에는 영향이 없고 뷰가 변경되어도 마찬가지임.
편리성 - 복잡한 질의를 뷰로 생성함으로서 관련 질의를 단순하게 작성함. 자주 작성하는 SQL문을 뷰를 이용해 편리하게 사용함.
보안성 - 직원의 급여정보와 같이 숨기고 싶은 정보가 존재하면 뷰를 생성할 때 해당 컬럼을 빼고 생성함으로써 사용자에게 정보를 감춤.
5.5.3. 예문
CREATE VIEW V_PLAYER_TEAM AS
SELECT P.PLAYER_NAME, P.POSITION, P.BACK_NO, P.TEAM_ID, T.TEAM_NAME
FROM PLAYER P, TEAM T
WHERE P.TEAM_ID = T.TEAM_ID;
SELECT PLAYER_NAME, POSITION, BACK_NO, TEAM_ID, TEAM_NAME
FROM V_PLAYER_TEAM
WHERE PLAYER_NAME LIKE '황%'
DROP VIEW V_PLAYER_TEAM;
6. 계층형 쿼리
6.1. 개념
- 테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해 사용함
- 게층형 데이터란 동일 테이블에 계층적으로 상위 데이터와 하위 데이터가 포함된 데이터임
6.2. 문법
SELECT ...
FROM TABLE
WHERE CONDITION AND CONDITION
START WITH CONDITION
CONNECT BY [NOCYCLE] CONDITION AND CONDITION
[ORDER SIBLINGS BY COLUMN, COLUMN......]
START WITH - 계증 구조 전개의 시작 위치, 즉, 루트 데이터를 지정함
CONNECT BY - 다음에 전개될 자식 데이터를 지정, 자식 데이터는 이 조건을 만족해야 함
PRIOR - CONNECT BY절에 사용되며 현재 읽은 컬럼을 지정함
PRIOR 자식 = 부모 : 자식 데이터에서 부모 데이터 방향으로 전개하는 순방향
PRIOR 부모 = 자식 : 부모 데이터에서 자식 데이터 방향으로 전개하는 역방향
NOCYCLE - 데이터를 전개하면서 이미 나타났던 동일한 데이터가 전개 중에 다시 나타나면 사이클이 형성되었다고 하고 런타임 오류를 발생시킴. NOCYCLE을 추가하면 사이클 발생 이후 데이터를 전개 안함
ORDER SIBLINGS BY - 형제 노드(동일 LEVEL) 사이에서 정렬을 수행함
WHERE - 모든 전개를 수행한 후 지정된 조건을 만족하는 데이터만 추출함
6.3. 가상 컬럼
LEVEL - 루트 데이터이면 1, 그 하위 데이터이면 2임. 리프 데이터까지 1씩 증가함
CONNECT_BY_ISLEAF - 전개 과정에서 해당 데이터가 리프 데이터면 1, 그렇지 않으면 0
CONNECT_BY_ISCYCLE - 전개 과정에서 자식을 갖는데, 해당 데이터가 조상으로서 존재하면 1, 그렇지 않으면 0임. 여기서 조상이란 자신으로부터 루트까지 경로에 존재하는 데이터임
SELECT LEVEL, LPAD(' ', 4 * (LEVEL-1)) || EMPNO 사원
, MGR 관리자
, CONNECT_BY_ISLEAF ISLEAF
, CONNECT_BY_ISCYCLE ISCYCLE
FROM EMP
START WITH MGR IS NULL
CONNECT BY PRIOR EMPNO = MGR;
6.4. 함수
SYS_CONNECT_BY_PATH - 루트 데이터로부터 현재 전개할 데이터 가지의 경로를 표시함 : SYS_CONNECT_BY_PATH(컬럼, 경로분리자)
CONNECT_BY_ROOT - 현재 전개할 데이터의 루트 데이터를 표시함. 단항 연산자임. : CONNECT_BY_ROOT(컬럼명)
SELECT CONNECT_BY_ROOT(EMPNO) 루트사원
, SYS_CONNECT_BY_PATH(EMPNO, '/') 경로
, EMPNO 사원, MGR 관리자
FROM EMP
START WITH MGR IS NULL
CONNECT BY PRIOR EMPNO = MGR;
참고출처
“SQL 전문가 가이드 (2013년) – 과목2. 3장. 제3절. 조인 수행 원리”, www.gurubee.net, 2013년 4월 6일 수정, 2023년 5월 19일 접속, http://www.gurubee.net/lecture/2388.
“SQL 전문가 가이드 (2013년) – 과목2. 1장. 제9절. 조인(JOIN)”, www.gurubee.net, 2013년 3월 18일 수정, 2023년 5월 19일 접속, http://www.gurubee.net/lecture/2375.
“SQL 전문가 가이드 (2013년) – 과목2. 4장. 제3절. 조인 기본 원리”, www.gurubee.net, 2013년 4월 9일 수정, 2023년 5월 19일 접속, http://www.gurubee.net/lecture/2405.
“SQL 전문가 가이드 (2013년) – 과목2. 2장. 제4절. 서브쿼리”, www.gurubee.net, 2013년 3월 25일 수정, 2023년 5월 19일 접속, http://www.gurubee.net/lecture/2380.
“SQL 전문가 가이드 (2013년) – 과목2. 2장. 제3절. 계층형 질의와 셀프조인”, www.gurubee.net, 2013년 3월 25일 수정, 2023년 5월 19일 접속, http://www.gurubee.net/lecture/2379.
“[DB이론] 뷰( View )”, victorydntmd.tistory.com, 2018년 2월 10일 수정, 2023년 5월 19일 접속, https://victorydntmd.tistory.com/131.
'DATABASE STUDY' 카테고리의 다른 글
| [MariaDB] innoDB CHARSET 과 COLLATE 의 개념과 종류별 특징 (0) | 2024.01.23 |
|---|---|
| [신입 SQL 교육 자료] GROUP BY-HAVING, ORDER BY, 윈도우함수, 테이블락, 트랜잭션, 동시성제어 (0) | 2023.05.31 |
| [신입 SQL 교육 자료] KEY, SEQUENCE, INDEX (0) | 2023.05.30 |
| [ ORACLE ] INSTR 함수를 사용해 문자열에서 특정 문자 인덱스를 찾고 SUBSTR 함수를 사용해 특정 구분자 사이의 문자열을 추출하기 (0) | 2023.04.06 |
| [MariaDB] 날짜형을 문자형으로, 문자형을 날짜형으로 변환하기 (0) | 2023.02.21 |

