
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- JSONObject 분할
- 마이바티스 트랜잭션
- executioncontext 변수 공유
- 아이템 리더 페이징 처리
- 선언적 트랜잭션 관리
- step 여러개
- 스프링배치 엑셀
- JSON 분리
- abstractpagingitemreader
- 트랜잭션 분리
- flatfileitemwriter
- 스프링 배치 5
- executioncontext
- api 아이템 리더
- spring batch 5
- 스프링배치 메타테이블
- 스프링배치 csv
- 읽기 작업과 쓰기 작업 분리
- step 값 공유
- JSON 분할
- Spring Batch
- job parameter
- 아이템 리더 커스텀
- spring batch 변수 공유
- mybatis
- JSONArray 분할
- step 사이 변수 공유
- stepexecutionlistener
- aop proxy
- 스프링 트랜잭션 관리
Archives
- Today
- Total
ebson
오라클 PL/SQL옵티마이저 본문
1. 옵티마이저 개념
- 사용자가 질의한 SQL문에 대해 최적의 실행 방법을 결정하는 역할을 수행함
- 최적의 실행 방법을 실행 계획이라고 함
- 최적의 실행 방법을 결정하는 것은 최소 일량으로 동일한 일을 처리하도록 하는 것임
- 실행계획을 수립하고 실행하는 DBMS의 소프트웨어임
- 규칙 기반 옵티마이저, 비용 기반 옵티마이저로 구분됨
- 데이터 사전의 오브젝트 통계, 시스템 통계를 사용해 비용 산정함
- 여러 개의 실행 계획 중 최저비용을 가진 계획을 선택해 SQL을 실행함
1.1. 옵티마이저 실행 절차
- 개발자가 작성한 SQL을 파신, 문법 검사 및 구문 분석함
- 구문 분석 후 옵티마이저가 규칙 기반 혹은 비용 기반으로 실행 계획을 수립함
- 기본적으로 비용 기반 옵티마이저를 사용해 실행 계획을 수립함
- 실행 계획이 수립되면 최종적으로 SQL을 실행하고 완료되면 데이터 인출함
⇒ SQL -> Parsing -> Optimizer -> 실행 계획 수립 -> SQL 실행
1.2. 옵티마이저 엔진
- Query Transformer : SQL을 효율적으로 실행하기 위해 변환함
- Estimator : 통계 정보를 사용해 SQL 실행 비용을 계산함, 총 비용은 최적의 실행 계획을 수립하기 위함임
- Plan Generator : SQL을 실행할 실행 계획을 수립함
1.3. 옵티마이저 종류
1.3.1 규칙기반 옵티마이저
- 규칙기반 옵티마이저는 실행계획을 수립할 때, 15개의 우선순위를 기준으로 수립함
- 최신 Oracle 버전은 비용 기반 옵티마이저를 기본적으로 사용함
- 오라클 10g부터 규칙기반 옵티마이저에 대한 지원을 중단함
- 휴리스틱 옵티마이저라고도 함
- 인덱스 구조, 연산자, 조건절 형태가 순서를 결정짓는 주요인임
- 데이터량, 값의 수, 컬럼값 분포, 인덱스 높이, 클러스터링 팩터같은 데이터 특성을 고려하지 못하므로 대용량 데이터 처리에는 부적합함. 예를 들어, 조건절에 인덱스가 있으면 풀 태이블 스캔과의 손익을 따지지 않고 무조건 인덱스를 사용하거나 부분범위 처리가 불가능한 상황이라면 풀 테이블 스캔을 하고 정렬하는 편이 나은데도 인덱스를 사용해 정렬함
- 즉, 예측 가능하고 일관성 있는 실행계획을 수립할 수 있으나, 데이터 특성에 따라 복잡한 비용 원리를 내포하고 있어 제어가 쉽지 않으므로 대용량 데이터베이스 환경에서는 규칙기반 옵티마이저를 보통 선호하지 않음
- 힌트를 줌으로써 규칙기반 옵티마이저로 실행하기

1.3.2 비용기반 옵티마이저
- 오브젝트 통계 및 시스템 통계를 사용해 총 비용을 계산함
- 총 비용이란 SQL문을 실행하기 위해 예상되는 소요시간 혹은 자원 사용량임
- 총 비용이 적은 쪽으로 실행 계획을 수립함
- 비용 기반으로 최적화를 수행함. 비용이란 쿼리를 수행하는데 소요되는 열량이나 시간을 의미함. I/O 요청 횟수 뿐만 아니라 CPU 연산 비용까지 감안하고 수행일량을 상대적인 시간 개념으로 환산해 비용을 평가함
- 미리 구해놓은 테이블과 인덱스에 대한 여러 통계 정보를 기초로 각 오퍼레이션 단계별로 비용을 예상하고 최저 비용 실행계획을 선택함. 레코드 개수, 블록 개수, 평균 행 길이, 컬럼 값의 수, 컬럼 값 분포, 인덱스 높이, 클러스터링 팩터 등이 오브젝트 통계 항목으로 사용됨
- 요약해, 사용자의 쿼리를 분석, 실행계획 탐색, 데이터 딕셔너리의 오브젝트 및 시스템 통계를 활용해 예상비용 산정, 최저비용 실행계획 선택의 순임
1.3.3 인덱스 스캔
- Unique Index SCAN : 인덱스의 키 값이 중복되지 않는 경우, 해당 인덱스를 사용할 때 생성함
- Ex) 인덱스 컬럼에 등가 조건으로 검색하기

- Index Range SCAN : SELECT 문에서 특정 범위를 조회하는 WHERE 문을 사용할 경우 발생 ex) like, between 등 -> 데이터 양이 적은 경우는 Table Full SCAN할 수 있음. Index Range SCAN은 인덱스의 Leaf Block의 특정 범위를 스캔한 것임
- Ex) 인덱스 컬럼에 범위 조건으로 검색하기
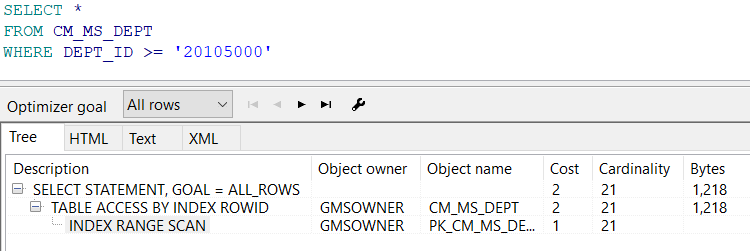
- Index Full SCAN : 인덱스에서 검색되는 인덱스 키가 많은 경우에 Leaf Block의 처음부터 끝까지 전체를 읽어 들임
Ex) 강제로 인덱스를 타게한 후, 인덱스 범위가 넓도록 조회하기

1.3.4 옵티마이저 조인
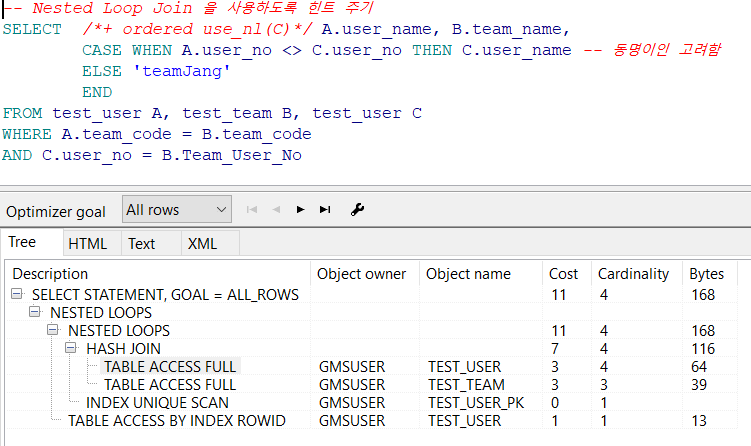
1.3.4.1 Nested Loop 조인
- 하나의 테이블에서 데이터를 먼저 찾고 그 다음 테이블을 조인하는 방식으로 실행함
- 먼저 조회되는 테이블을 외부 테이블이라고 하고 다음에 조회되는 테이블을 내부 테이블이라고 함
- 외부 테이블의 크기가 작은 것을 먼저 찾아야 데이터가 스캔되는 범위를 줄일 수 있음
- RANDOM ACCESS가 발생하는데 이것은 성능 지연을 초래함
- use_nl 힌트 사용하기 ->
SELECT /*+ ordered use_nl(b) */ *
FROM EMP2 a, DEPT2 b
WHERE a.DEPTNO = b.DEPT
AND a.DEPTNO = 10;
- ⇒ user_nl() 힌트를 사용하면 Nested Loop 조인을 실행함. 인자로 전달한 테이블을 외부테이블로 먼저 스캔함. ordered 힌트는 FROM 절에 나오는 테이블 순서대로 조인을 하게 하는 것임 -> user_nl, user_merge, user_hash와 함께 사용함
1.3.4.2 Sort Merge 조인
- 두 개의 테이블을 SORT_AREA 라는 메모리 공간에 모두 로딩하고 SORT를 수행함
- 두 개의 테이블에 대해 SORT가 완료되면 두 개의 테이블을 병합함
- Sort Merge 조인은 정렬이 발생하기 때문에 데이터양이 많아지면 성능이 떨어짐
- 정렬 데이터 양이 너무 많으면 정렬은 임시 영역에서 수행되고 임시 영역은 디스크에 있기 때문에 성능이 크게 떨어짐
- 양쪽 테이블 처리 범위를 각자 Access함 -> 각자 정렬함 -> 정렬한 결과를 차례로 Scan하며 연결고리 조건으로 Merge함
- use_merge() 힌트를 사용해 Sort Merge 조인을 실행하게 하기

1.3.4.3 Hash 조인
- 두 개의 테이블 중에서 작은 테이블을 HASH 메모리에 로딩하고 두 개의 테이블의 조인 키를 사용해 해시 테이블을 생성함
- 해시 함수를 사용해 주소를 계산하고 해당 주소를 사용해 테이블을 조인하기 때문에 CPU 연산을 많이함
- 특히 HASH 조인 시에는 선행 테이블이 충분히 메모리에 로딩되는 크기여야 함
2. 사용이유
- 개발자가 작성한 SQL문을 최적의 성능으로 실행하기 위해서는 실행계획이 중요함
- 옵티마이저의 실행계획이 비효율적이면 개발자는 SQL을 개선할 수 있음
- use_hash() 힌트를 사용해 Hash 조인을 실행하게 하기

3. 사용방법
- 옵티마이저는 SQL실행 계획을 PLAN_TABLE에 저장함
- SQL 개발자는 PLAN_TABLE을 조회해 실행 계획을 확인할 수 있음
- PL/SQL Developer 에서는 F5버튼으로 실행계획을 조회할 수 있음
- 옵티마이저에게 실행 계획을 변경하도록 요청할 수 있는 힌트를 사용함
4. 옵티마이저 힌트
- 힌트 안에 인자를 나열할 때, ‘,’(콤마)를 사용할 수 있지만, 힌트와 힌트 사이에는 사용하면 안됨
- 테이블을 지정할 때 스키마명까지 명시하면 안됨
- FROM절 테이블 명에 Alias(별명)을 지정했다면, 힌트에도 반드시 Alias를 사용함
- 문법적으로 맞지 않거나, 잘못된 테이블명, 별명 또는 인덱스명을 참조하거나, 논리적으로 불가능한 액세스를 시도하는 경우에 옵티마이저는 힌트를 따르지 않음
- 일반적인 사용 원칙은 가급적 힌트 사용을 자제하는 것임
참고 출처
https://dataonair.or.kr/db-tech-reference/d-guide/sql/?mod=document&uid=354
https://jione-e.tistory.com/16
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=gglee0127&logNo=221301903122
'DATABASE STUDY' 카테고리의 다른 글
| 오라클 NULL (0) | 2022.08.28 |
|---|---|
| 오라클 SEQUENCE (0) | 2022.08.28 |
| 오라클 SQL - JOIN (1) | 2022.08.28 |
| 오라클 SQL - SUBQUERY (1) | 2022.08.28 |
| 마리아DB에서 오라클 PIVOT 기능 사용하기 (0) | 2022.08.28 |
'DATABASE STUDY' Related Articles
more

Comments